Distillation 简介
本文简单了描述机器学习中的蒸馏(distillation)技术的原理,distillation 可简单分为 model distillation 和 feature distillation。顾名思义,蒸馏是对原来的模型 / 特征进行了压缩,其原因可能是为了减少模型的大小(model distillation)、或者某些特征只能在 training 时获取,serving 无法获取 (feature distillation);在实际业务中可根据具体场景灵活地应用这两类技术。
基本原理
Distillation 可分为 Model Distillation 和 Feature Distillation,其思想都是在训练时同时训练两个模型:teacher 模型和 student 模型,而在 serving 时只用 student 模型。这里的假设是:teacher 模型比起 student 模型,在模型结构上更复杂 (Model Distillation) ,或在特征集上更为丰富 (Feature Distillation) ;因此其准确率也会比 student 模型要好。
如下图所示是 Model Distillation 和 Feature Distillation 示例 (下面的图和公式基本摘自 Privileged Features Distillation for E-Commerce Recommendations)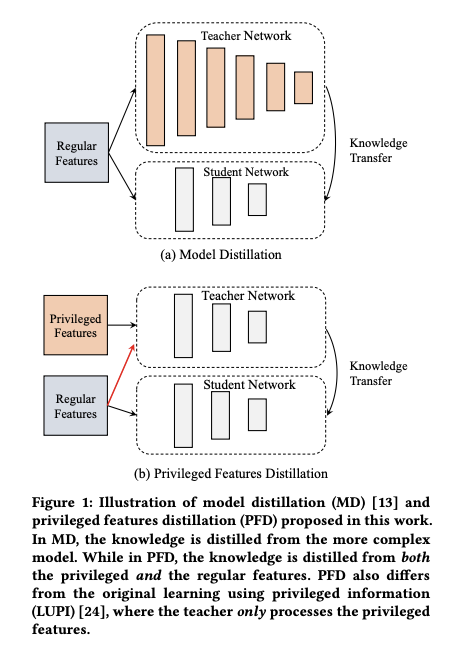
那如何利用 teacher 模型指导 student 模型学得更好?基本的做法是将 teacher 模型的输出作为 soft label (相对于作为 ground truth 的 hard label), 为 student 模型添加额外的 loss 项;如下公式 (1) 所示
\[\begin{align} \min_{W_s} (1-\lambda)L_s(y, f_s(X;W_s))+\lambda*L_d(f_t(X;W_t),f_s(X;W_s)) \tag{1} \end{align}\]
上式中各项符号含义如下
- \(f_s(X; W_s)\) :student 模型的预估值
- \(f_t(X;W_t)\) : teacher 模型的预估值
- \(L_s\) :student 模型原始的 loss
- \(L_d\) :利用 teacher 模型预估值输出作为 soft label 计算的 distillation loss;
- \(\lambda\):平衡 \(L_s\) 和 \(L_d\) 的超参
上面公式(1)是 Model Distillation 的典型做法,可以看到输入 teacher 模型和 student 模型的特征都是相同的即 \(X\) ;而公式 (2) 描述的 Feature Distillation 则认为 teacher 模型的特征(\(X^*\))比 student 模型的特征 (\(X\)) 更为丰富,
\[\begin{align} \min_{W_s} (1-\lambda)L_s(y, f_s(X;W_s))+\lambda\*L_d(f_t(X^\*;W_t),f_s(X;W_s)) \tag{2} \end{align}\]
上面两条公式是 Distillation 的核心思想了,且在使用理论上应该首先训练好 teacher 网络,再训练 student 网络;但是在实际训练的时候,为了加快训练速度,会令 teacher 模型和 student 模型同时进行训练;因此最终的损失函数变为了如下公式 (3) 形式,其中 \(L_s\) 和 \(L_t\) 是 logloss, 而 \(L_d\) 是 cross entropy loss
\[\begin{align} \min_{W_s, W_t} (1-\lambda)L_s(y, f_s(X;W_s)) + \lambda\*L_d(f_t(X^\*;W_t),f_s(X;W_s)) + L_t(y, f_t(X^\*;W_t))\tag{3} \end{align}\]
综上,在 training 和 serving 时的模型结构分别如下所示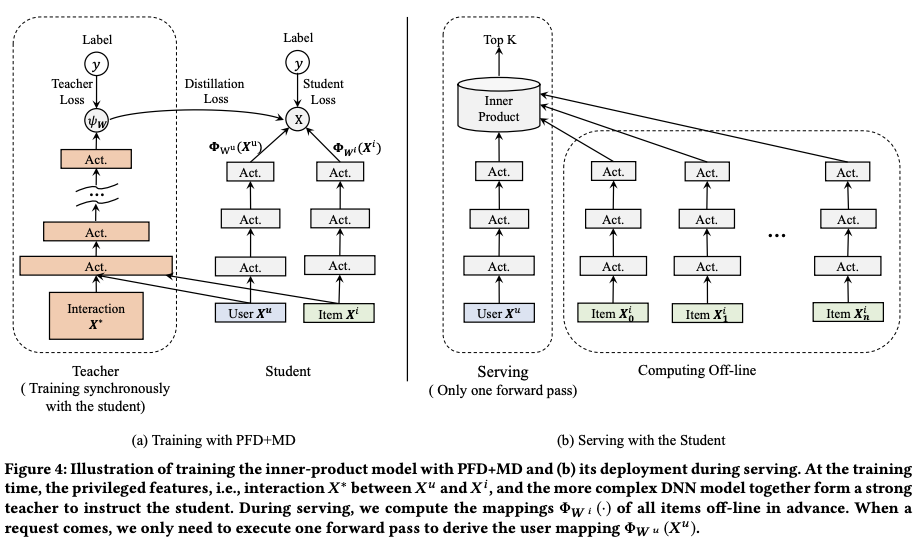
训练注意事项
上面提到,distillation 需要训练 teacher 和 student 两个网络,因此也有两种训练模式:
(1)先训练 teacher 网络,再训练 student 网络,也被称为 asynchronous training (2)同时训练 teacher 网络和 student 网络,也被称为 synchronous training
理论上应该采用方式 (1), 但是由于需要串行训练两个模型,会导致训练的时间过长 , 因此才提出了方式(2)的方法;而方式 (2) 会带来训练效果不稳定的问题, 其原因是在 teacher 在训练初期,其效果往往还不好,而将其输出结果作为 label 很容易导致 student 网络学飞了
因此更常用的做法在这两个之间做个权衡,基本做法就是在训练的初期,将公式 (3) 中的 \(\lambda\) 设为 0,然后后面逐渐增大 \(\lambda\) 这个值
上面提到的 paper 在这点上提出了一个更简单策略,就是在 \(k\) 个 step 后才让 teacher 网络的输出作为 loss 影响 student 网络,\(k\) 是一个拍定的超参,因此其详细训练方式如下
实现
tensorflow 提供的一个 distillation 的实现 distillation.py,使用见 stack-overflow 上的 这个回答
核心代码如下所示,注释写得已经非常清晰了,下面默认的模式是先训练好了 Teacher 网络,再训练 Student 网络,也就是上面提到的 asynchronous training 模式;但是也可以比较容易将下面的逻辑改成 synchronous training 的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52### Teacher Network
with tf.variable_scope("teacher"):
teacher_outputs = self.teacher_model.body(features)
tf.logging.info("teacher output shape: %s" % teacher_outputs.get_shape())
teacher_outputs = tf.reduce_mean(teacher_outputs, axis=[1, 2])
teacher_logits = tf.layers.dense(teacher_outputs, hp.num_classes)
teacher_task_xent = tf.nn.softmax_cross_entropy_with_logits_v2(
labels=one_hot_targets, logits=teacher_logits)
outputs = teacher_logits
if is_distill:
# Load teacher weights
tf.train.init_from_checkpoint(hp.teacher_dir, {"teacher/": "teacher/"})
# Do not train the teacher
trainable_vars = tf.get_collection_ref(tf.GraphKeys.TRAINABLE_VARIABLES)
del trainable_vars[:]
### Student Network
if is_distill:
with tf.variable_scope("student"):
student_outputs = self.student_model.body(features)
tf.logging.info(
"student output shape: %s" % student_outputs.get_shape())
student_outputs = tf.reduce_mean(student_outputs, axis=[1, 2])
student_logits = tf.layers.dense(student_outputs, hp.num_classes)
student_task_xent = tf.nn.softmax_cross_entropy_with_logits_v2(
labels=one_hot_targets, logits=student_logits)
teacher_targets = tf.nn.softmax(teacher_logits / hp.distill_temperature)
student_distill_xent = tf.nn.softmax_cross_entropy_with_logits_v2(
labels=tf.stop_gradient(teacher_targets),
logits=student_logits / hp.distill_temperature)
# scale soft target obj. to match hard target obj. scale
student_distill_xent *= hp.distill_temperature**2
outputs = student_logits
# Summaries
tf.summary.scalar("distill_xent", student_distill_xent)
if not is_distill:
phase_loss = teacher_task_xent
else:
phase_loss = hp.task_balance * student_task_xent
phase_loss += (1 - hp.task_balance) * student_distill_xent
losses = {"training": phase_loss}
outputs = tf.reshape(outputs, [-1, 1, 1, 1, outputs.shape[1]])
return outputs, losses